Storage¶
服务概述¶
Storage 是新浪云为开发者提供的分布式对象存储服务,可以用来保存资源文件、备份数据等。
创建 Bucket¶
Bucket 是一个容器,这个容器中可以存放各种数据(Object)。上传任何数据之前需先创建 Bucket。您可以在控制台 『应用/存储与CDN/Storage 』中创建 Bucket 。

Bucket 中存储的内容叫做 Object ,可以是文本、多媒体、二进制等任意类型的数据文件。
访问控制¶
Bucket 可以根据业务需求设置不同的访问权限。按照权限大小可以有以下几种:
私有
Bucket 的 Object 是完全私有的,可以用来保存应用的备份数据等。私有 Bucket 中的数据只可以通过 SDK 读取或者通过 SDK 中的 getTempUrl 获取一个临时的访问 URL 来让用户访问,这个 URL 有过期时间,到期后 URL 会失效,无法再访问。例:http://myapp-mybucket.stor.sinaapp.com/path/to/object?temp_url_sig=1e5c3d0a6af2ede4e327a44a7ef4a72e3423f1fb&temp_url_expires=1472711334
公开+防盗链
对于公有的 Bucket 也可以开启防盗链、设置只允许自己的应用域名来访问 Bucket 中的 Object。服务器会根据 HTTP 请求里的 Referer 头来判断一个请求是否在允许的域名里,不在会 302 跳转到您设置的跳转地址。
公开
用户可以直接通过 Object 的公开 URL 来访问。 例:http://myapp-mybucket.stor.sinaapp.com/path/to/object
浏览器缓存 目前几乎所有的浏览器都有本地缓存机制。开发者可以通过控制 Object 的浏览器缓存过期时间,也就是设置 Object 的 HTTP 响应的 Cache-Control 和 Expires 这两个 HTTP Header,来提升 Web 应用的性能,减轻服务端的资源消耗。如果用户没有设置 Bucket 或者 Object 的浏览器缓存过期时间,Storage 默认的时间是 2 小时。
上传、下载、管理¶
创建完 Bucket 之后,你可以通过以下方法以及 API 接口往 Bucket 中存数据。
Web¶
你可以直接通过 Storage 的 Web 控制台来管理创建的 Bucket。
FTP¶
Storage 提供了一个 FTP 管理接口,您可以使用任意 FTP 客户端来操作。FTP 服务器的连接信息如下:
- 地址: ftp.sinas3.com
- 端口: 10021
- 用户名:应用的 AccessKey
- 密码:应用的 SecretKey
Cyberduck¶
在 Windows 和 Mac 系统下面,你可以使用 Cyberduck 来操作 Storage。
下载地址: http://cyberduck.io
打开 Cyberduck,点击左上角的“新建连接”。
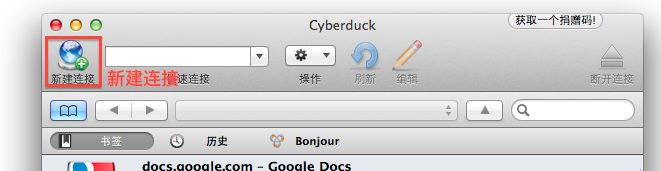
在弹出的对话框中填写连接相关信息:
类型:Swift。
服务器:auth.sinas3.com
端口:443(默认)
用户名:应用 AccessKey(在应用“汇总信息”页面中查看)
密码:应用 SecretKey(在应用“汇总信息”页面中查看)
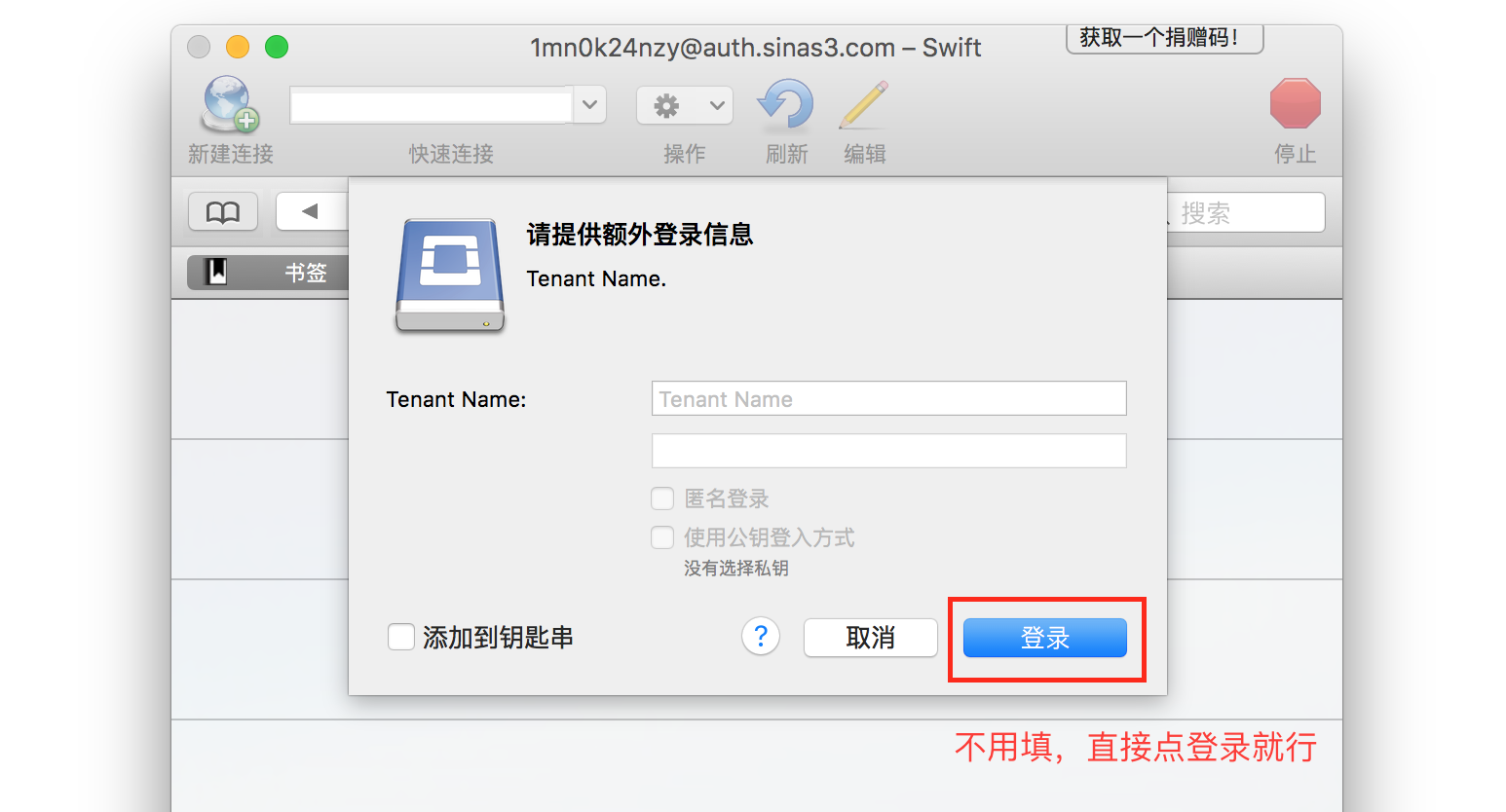
填写完成后点击连接。如果弹出 auth.sinas3.com,api.sinas3.com 相关证书问题,请选择信任。

有些版本的 Cyberduck 会弹出下面的对话框,忽略,直接点登录就可以了。
连接完成后,将会看到该应用 Storage 的所有 Bucket 列表:

操作:双击 Bucket 名称,可进入 Bucket,列出文件和文件夹,此时,可进行文件的上传、下载、以及删除操作。
Swift 命令行工具¶
注解
以下文档以 Ubuntu 系统为例。
首先,安装客户端。
$ apt-get install python-pip;
$ pip install python-swiftclient;
安装完成后,你可以通过 swift 这个命令来对应用的 Storage 进行操作。在每次使用 swift 之前,请首先执行以下命令将以下配置信息加入到环境变量中去。
$ export ST_AUTH='https://auth.sinas3.com/v1.0'
$ export ST_USER='AccessKey'
$ export ST_KEY='SecretKey'
获取访问 URL¶
你可以在 Storage 控制台中直接在对应的 Object 上右击,选择“复制链接”来获取 Object 的访问 URL,如果是公开的 Bucket,URL 为 Object 的公开 URL,如果是私有 Bucket,该 URL 为一个 5 分钟后过期的临时 URL。
在代码里,你也可以通过 SDK 中的 getURL 或者 getTempurl 来获取 Object 的公开 URL和临时 URL。
API使用手册¶
-
class
sae.storage.Error¶ Storage异常类。
-
class
sae.storage.Connection(accesskey=ACCESS_KEY, secretkey=SECRET_KEY, account=APP_NAME, retries=3)¶ Connection类
参数: - accesskey – 可选。storage归属的应用的accesskey,默认为当前应用。
- secretkey – 可选。storage归属的应用的secretkey,默认为当前应用。
- account – 可选。storage归属的应用的应用名,默认为当前应用。
- retries – 请求失败时重试的次数。
-
get_bucket(bucket)¶ 获取一个bucket类的instance。
参数: bucket – bucket的名称。
-
class
sae.storage.Bucket(bucket, conn=None)¶ Bucket类,封装了大部分的storage操作。
参数: - bucket – bucket的名称。
- conn – 可选。一个sae.storage.Connection的实例。
-
put(acl=None, metadata=None)¶ 创建一个bucket。
参数: - acl – bucket的访问权限。
- metadata – 需要保存的元数据,metadata应该是一个dict,例如 {‘color’: ‘blue’} 。
-
post(acl=None, metadata=None)¶ 修改bucket的acl和metadata。其中metadata的修改为增量修改。
-
list(prefix=None, delimiter=None, path=None, limit=10000, marker=None)¶ 列出bucket中的object。
参数: - prefix – object名称的前缀。
- delimiter – 分割字符。折叠包含该分割字符的条目。
- path – 返回路径path下的全部objects。等价于prefix为path,delimiter为/。
- limit – 最大返回的objects条数。
- marker – 返回object名为marker后面的结果(不包含marker)。
返回: 符合条件的objects的属性的一个generator。
-
stat()¶ 返回: 当前bucket的属性信息。
-
delete()¶ 删除bucket。被删除的bucket必须已经清空(没有任何object)。
-
put_object(obj, contents, content_type=None, content_encoding=None, metadata=None)¶ 创建或更新一个object。
参数: - obj – object的名称。
- contents – object的内容,可以是字符串或file-like object。
- content_type – object的mime类型。
- content_encoding – object的encoding。
- metadata – object的元数据。
-
post_object(obj, content_type=None, content_encoding=None, metadata=None)¶ 更新object的一些属性。
注意:object的metadata的更新是全量的,和container的增量修改不一样。
-
get_object(obj, chunk_size=None)¶ 获取object的内容和属性信息。
参数: - obj – object的名称。
- chunk_size – 不返回object的全部内容,而是返回一个文件内容的generator,每次iterate返回chunk_size大小的数据。
返回: 一个tuple (obj的属性信息, object的内容)。
-
get_object_contents(obj, chunk_size=None)¶ 获取object的内容。
参数同get_object,只返回object的内容。
-
stat_object(obj)¶ 获取object的属性信息。
-
delete_object(obj)¶ 删除object。
-
generate_url(obj)¶ 返回object的public url。
模拟storage为文件系统¶
from sae.ext.storage import monkey
monkey.patch_all()
以上代码会将storage ‘挂载’到 /s/ 目录下,每个bucket为这个目录下的一个子目录。用户可以使用 /s/<bucket-name>/<object-name> 这样形式的路径通过文件系统接口来访问storage的中的object。
目前支持(patch)的文件系统接口函数为: open, os.listdir, os.mkdir, os.path.exists, os.path.isdir, os.open, os.fdopen, os.close, os.chmod, os.stat, os.unlink, os.rmdir
使用示例¶
在新浪云线上运行环境中操作storage
>>> # 创建一个bucket的instance
>>> from sae.storage import Bucket
>>> bucket = Bucket('t')
>>> # 创建该bucket
>>> bucket.put()
>>> # 修改该bucket的acl和缓存过期时间。
>>> bucket.post(acl='.r:.sinaapp.com,.r:sae.sina.com.cn', metadata={'expires': '1d'})
>>> # 获取该bucket的属性信息
>>> attrs = bucket.stat()
>>> print attrs
{'acl': '.r:.sinaapp.com,.r:sae.sina.com.cn',
'bytes': '0',
'metadata': {'expires': '1d'},
'objects': '0'}
>>> attrs.acl
'.r:.sinaapp.com,.r:sae.sina.com.cn'
>>> # 存取一个字符串到bucket中
>>> bucket.put_object('1.txt', 'hello, world')
>>> # 获取object的public url
>>> bucket.generate_url('1.txt')
'http://pylabs-t.stor.sinaapp.com/1.txt'
>>> # 存取一个文件到bucket中
>>> bucket.put_object('2.txt', open(__file__, 'rb'))
>>> # 列出该bucket中的所有objects
>>> [i for i in bucket.list()]
[{u'bytes': 12,
u'content_type': u'text/plain',
u'hash': u'e4d7f1b4ed2e42d15898f4b27b019da4',
u'last_modified': u'2013-05-22T05:09:32.259140',
u'name': u'1.txt'},
{u'bytes': 14412,
u'content_type': u'rb',
u'hash': u'99079422784f6cbfc4114d9b261001e1',
u'last_modified': u'2013-05-22T05:12:13.337400',
u'name': u'2.txt'}]
>>> # 获取object的所有属性
>>> bucket.stat_object('1.txt')
{'bytes': '12',
'content_type': 'text/plain',
'hash': 'e4d7f1b4ed2e42d15898f4b27b019da4',
'last_modified': '2013-05-22T05:09:32.259140',
'metadata': {},
'timestamp': '1369199372.25914'}
>>> # 取object的内容
>>> bucket.get_object_contents('1.txt')
'hello, world'
>>> # 取文件的内容,返回generator
>>> chunks = bucket.get_object_contents('2.txt', chunk_size=10)
<generator object _body at 0x95ec20c>
>>> chunks.next() # 显示第一个chunk
'\n# Copyrig'
>>> # 删除objects
>>> bucket.delete_object('1.txt')
>>> bucket.delete_object('2.txt')
>>> # 删除bucket
>>> bucket.delete()
storage中不支持创建实际的目录,但是用户可以通过在object name中加入 / 来模拟目录结构。例如:
>>> bucket.put_object('a/1.txt', '')
>>> bucket.put_object('a/b/2.txt', '')
>>> # 列出根目录下的所有objects。
>>> [i for i in bucket.list(path='')]
[{u'bytes': None,
u'content_type': None, # content_type为None表示这是一个子目录
u'hash': None,
u'last_modified': None,
u'name': 'a/'}]
>>> # 列出a目录下的objects
>>> [i for i in bucket.list(path='a/')]
[{u'bytes': 0,
u'content_type': u'text/plain',
u'hash': u'd41d8cd98f00b204e9800998ecf8427e',
u'last_modified': u'2013-05-23T03:01:59.051030',
u'name': u'a/1.txt'},
{u'bytes', None,
u'content_type': None, # content_type为None表示这是一个子目录
u'hash': None,
u'last_modified': None,
u'name': u'a/b/'}]
注解
在list目录(除了根目录)时路径的末尾要带上 / 。